Business
Implement differential privacy to power up data sharing and cooperation

Traditionally, companies have relied upon data masking, sometimes called de-identification, to protect data privacy. The basic idea is to remove all personally identifiable information (PII) from each record. However, a number of high-profile incidents have shown that even supposedly de-identified data can leak consumer privacy.
In 1996, an MIT researcher identified the then-governor of Massachusetts’ health records in a supposedly masked dataset by matching health records with public voter registration data. In 2006, UT Austin researchers re-identifed films watched by thousands of individuals in a supposedly anonymous dataset that Netflix had made public by combining it with data from IMDB.
In a 2022 Nature article, researchers used AI to fingerprint and re-identify more than half of the mobile phone records in a supposedly anonymous dataset. These examples all highlight how “side” information can be leveraged by attackers to re-identify supposedly masked data.
These failures led to differential privacy. Instead of sharing data, companies would share data processing results combined with random noise. The noise level is set so that the output does not tell a would-be attacker anything statistically significant about a target: The same output could have come from a database with the target or from the exact same database but without the target. The shared data processing results do not disclose information about anybody, hence preserving privacy for everybody.
To implement differential privacy, one should not start from scratch, as any implementation mistake could be catastrophic for the privacy guarantees.
Operationalizing differential privacy was a significant challenge in the early days. The first applications were primarily the provenance of organizations with large data science and engineering teams like Apple, Google or Microsoft. As the technology becomes more mature and its cost decreases, how can all organizations with modern data infrastructures leverage differential privacy in real-life applications?
Differential privacy applies to both aggregates and row-level data
When the analyst cannot access the data, it is common to use differential privacy to produce differentially private aggregates. The sensitive data is accessible through an API that only outputs privacy-preserving noisy results. This API may perform aggregations on the whole dataset, from simple SQL queries to complex machine learning training tasks.
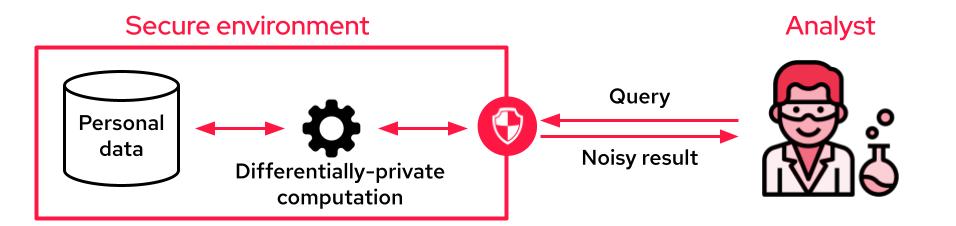
A typical setup for leveraging personal data with differential privacy guarantees. Image Credits: Sarus
One of the disadvantages of this setup is that, unlike data masking techniques, analysts no longer see individual records to “get a feel for the data.” One way to mitigate this limitation is to provide differentially private synthetic data where the data owner produces fake data that mimics the statistical properties of the original dataset.


Google lays off workers, Tesla cans its Supercharger team and UnitedHealthcare reveals security lapses

Loneliness in kids: Screen time may play a role

The greatest films on Prime Video right now

ICONIQ Growth raises $5.75B seventh flagship fund

Luminar cuts 20% of staff and outsources lidar production

Apple Watch Series 9 vs. SE: A smartwatch skeptic tested both for 13 days

Google dubs Epic’s demands from its antitrust win ‘unnecessary’ and ‘far beyond the scope’ of the verdict

Apple: pay attention to emerging markets, not falling China sales

Greatest Star Wars Day deals and new releases 2024: Shop May the 4th sales
Danti’s natural language search engine for Earth data soars with $5M in new funding

NASA discovered bacteria that wouldn’t die. Now it’s boosting sunscreen.

API startup Noname Security nears $500M deal to sell itself to Akamai

US think tank Heritage Foundation hit by cyberattack

How to watch ‘Argylle’: When and where is it streaming?

Tesla drops prices, Meta confirms Llama 3 release, and Apple allows emulators in the App Store

Meta to close Threads in Turkey to comply with injunction prohibiting data-sharing with Instagram

Tesla layoffs hit high performers, some departments slashed, sources say

Former top SpaceX exec Tom Ochinero sets up new VC firm, filings reveal

TechCrunch Mobility: Cruise robotaxis return and Ford’s BlueCruise comes under scrutiny

Consumer Financial Protection Bureau fines BloomTech for false claims
Google lays off workers, Tesla cans its Supercharger team and UnitedHealthcare reveals security lapses
Loneliness in kids: Screen time may play a role
The greatest films on Prime Video right now
ICONIQ Growth raises $5.75B seventh flagship fund
Luminar cuts 20% of staff and outsources lidar production
Apple Watch Series 9 vs. SE: A smartwatch skeptic tested both for 13 days
Google dubs Epic’s demands from its antitrust win ‘unnecessary’ and ‘far beyond the scope’ of the verdict
Apple: pay attention to emerging markets, not falling China sales
Greatest Star Wars Day deals and new releases 2024: Shop May the 4th sales
Danti’s natural language search engine for Earth data soars with $5M in new funding
-

 Business7 days ago
Business7 days agoHumanoid robots are learning to fall well
-

 Entertainment6 days ago
Entertainment6 days ago2024 summer TV preview: 33 TV shows to watch this summer
-

 Business6 days ago
Business6 days agoGoogle Gemini: Everything you need to know about the new generative AI platform
-

 Business4 days ago
Business4 days agoHaun Ventures is riding the bitcoin high
-

 Entertainment5 days ago
Entertainment5 days ago‘Bridgerton’: Everything you need to remember before Season 3
-

 Entertainment4 days ago
Entertainment4 days agoHands-on with the Claude AI app: It’s pleasant to use, but janky
-

 Entertainment3 days ago
Entertainment3 days ago5 essential gadgets for turning your home into a self-care sanctuary
-

 Business6 days ago
Business6 days agoIndian ride-hailing giant Ola cuts 180 jobs in profitability push